
Correspondence analysis is an exploratory data analysis method for discovering relationships between two or more categorical variables. It is very often used for visualizing survey data since if the matrix is large enough (which could be due to large number of variables but also possible with small number of variables with high cardinality) visual inspection of tabulated data or simple statistical analysis cannot sufficiently explain its structure. Correspondence analysis can remarkably simplify representation of such data by projecting both row and column variables into lower dimensional space that can often be visualized as a scatter plot at a small loss of fidelity.
Let’s take a look at an example. Below is the data from 2014 Auto Brand Perception survey by Consumer Reports where 1578 randomly selected adults were asked what they considered exemplar attributes for different car brands. Respondents picked all that apply from among the list that consisted of : Style, Performance, Quality, Safety, Innovation, Value and Fuel Economy.
We can convert this data into a contingency table in R and do a chi-square test which tells us that there is statistically significant association between car brands and their perceived attributes.
chisq.test(table(yourDataFrameGoesHere))
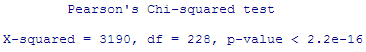
But often this is not sufficient since my goal is to understand how different car makers are perceived to learn how people see my brand, how I compare with the competition, how to competitively position an existing product or bring a new product in the market to fill a gap.
Let’s visualize this as a cross-tab in Tableau.

Even though there are only 7 choices and a single question in the survey, this table is hard to interpret.
Let’s apply correspondence analysis and see what our scatter plot looks like. Here blue dots are cars. Blue points closer to each other are more similar than points farther away. Red items (e.g. Style being hovered over in the screenshot) are the attributes. The axes themselves do not distinguish independent dimensions for discriminating categories so attributes are useful in orienting yourself when looking at the chart and help assign names to different areas of the scatter plot. If you imagine a line extending from the center of the plot towards each of the red points, the distance of blue points to the lines indicate how related they are to the particular attribute. For example for Volvo, safety is the the perception that dominates. Same can be said for Kia and Value. But Subaru is considered safe, have good quality and value while Porsche and Ferrari are mostly associated with attributes Style and Performance, roughly the same amount.

This scatter plot explains 70% of the variance in the data. While it doesn’t capture everything, it is a lot easier to consume than cross-tabulation.

The rows and columns used in computing the principal axes of the low-dimensional representation are called active points. Passive (supplementary) points/variables are projected onto the plot but not taken into account when computing the structure of the plot itself. For example if there are two new cars in the market and you want to see their relative positioning in an existing plot, you can add them as supplementary points. If there are outliers, you can also choose to make them into supplementary points not to skew the results. Supplementary variables on the other hand are typically exogenous variables e.g. the age group or education level of the survey participant. In some cases you may prefer generating multiple plots instead e.g. one per gender. You can mark a column or row as supplementary using supcol and support arguments in ca function call e.g. ca(mydata,supcol=c(1,6)) makes 1st and 6th columns in the table supplementary.
You can add more to this chart to explore more. For example, you can put price of the car or safety rating on color and see whether they align with the perceived value or safety. For example Tesla, Ford and Fiat are all associated with value while Tesla is not a budget car. Similarly Volvo and Tesla both have a 5 star safety rating but consumers associate Volvo much more with safety than any other brand. If you have multiple years of data, you can put years on the Pages Shelf and watch how perception changed over time, whether your marketing campaigns were effective in moving it in a direction you wanted.
Correspondence analysis use cases are not limited to social sciences and consumer research. In genetics for example microarray studies use MCA to identify potential relationships between genes. Let’s pick our next example from a different domain.
If there are multiple questions in your survey, you can use Multiple Correspondence Analysis (MCA) instead. Our data for this example contains categorical information about different organisms. Whether they fly, photosynthesize, have a spine….

For a moment, imagine the first column doesn’t exist so you have no knowledge about what organism each row is. How easy would it be to understand if there are groups in the data based on these attributes?
Let’s apply MCA to this dataset. In this case I put the attributes in the secondary axis, hid their marks and made their labels larger. I also applied some jitter to deal with overlapping marks.
I can clearly see groups like birds, mammals, plants, fungi and shellfish. If the data wasn’t labeled, I would be able to associate them looking at the chart and by examining the common attributes of adjacent points start developing an understanding of what type of organisms they might be.

You can download the sample workbook from HERE.

Pingback: CORRESPONDENCE ANALYSIS IN TABLEAU WITH R – Bora Beran – DIGR
Hi Bora,
A very nice blog on Correspondence Analysis in Tableau with R. I am trying the same.
This is the error i get when i try the MCA part
Error in mjca(as.data.frame(do.call(cbind, sdt)), abbrev = T) : unused argument (abbrev = T)
Regards,
Ren.
I have multiple questions that i am trying to do some correspondence analysis on for internal surveys. how to i add these questions. In the example i see only Attribute and Organism.
How could i use say Name and the 5 or 6 questions that we ask?
Regards,
Ren.
It’s nice and working
Thanks for sharing this Bora Beran.
Regards,
Naveen
Really Great
Hi Bora, thank you so much for sharing this in detail. May I ask you a favor? Can you please share me how the data source, Cars (Survey), is like? Just wondering how all the process is. Once again, this is incredible. Best, Toshi
you need to structure your data source like the following by column : Variables (fuel, energy), cars type, values. you can do that on R by using cast package.
Hi Bora, thank you for sharing this inspiring method.
However when I tried to duplicate, I always take this error “Error in seq_len(p) : argument must be coercible to non-negative integer”. Do you have any idea why this occurs?
Regards,
Damla
Hello DAMLA,
you need for any calculated field you have created and placed on ”Reperes” modify the table calculation and specify it on your rows and columns.
I think that it will help you
Regards,
John
The example worksheet was incomplete so not able to review the process or results.